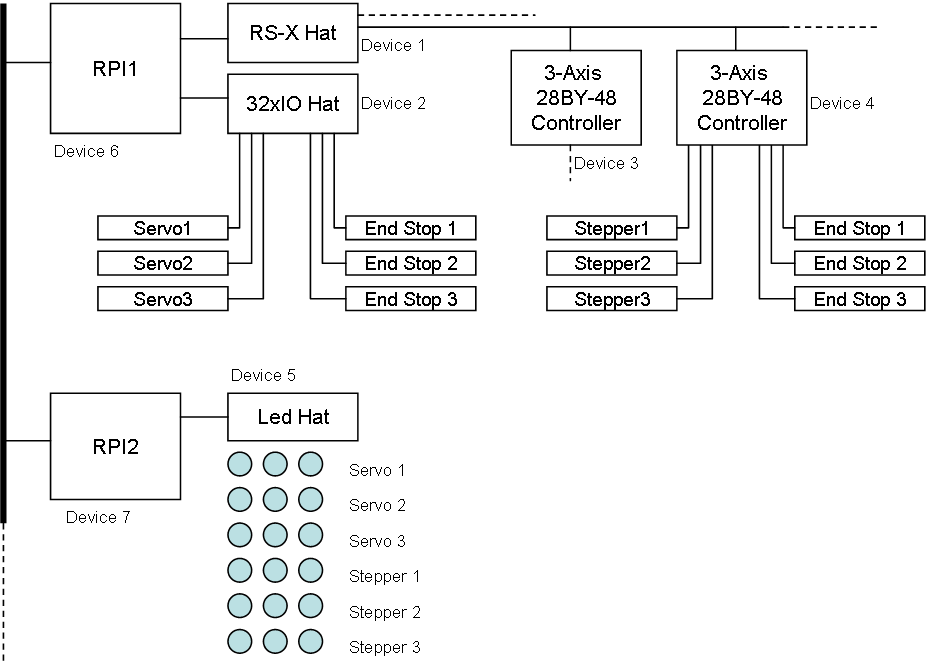
Distributed processing is at the core of what we do in Plain. A module depends on other modules and can use that as part of it’s own logic. A simple function call or an event can connect with a different process that may be local on the same device or located on a different device.
The Plain developer do not need to be concerned about the details of how this happens. This is an important abstraction that also is a core Plain concept – we focus on what we do and leave the details of how to C/C++ developers. This makes Plain an extension to – not an replacement of – host languages.
Distributed Processing needs a communication protocol to be able to communicate between processes on the same or different devices. This is what easyIPC does, it enable network wide communication between devices regardless wherever this is Ethernet, RS485, CAN or some wireless protocol. easyIPC allows us to send messages with content that only need to be understood by the sender and receiver, In this case the Plain VM.
use MyHostModule
module MydeviceModule
MyHostModule.Println ("Hello World")
End
This example assume we have a plain module located top-side that is called from a module located on a device.
What will happen in the example above is that MyHostModule.println is assembled into a Call Instruction. As the “Call” in this case is to a different module we will in effect be calling a C function that communicate with the other module. In this case the C code need to detect that this is a remote process and assemble an easyIPC message that is sent. As we send this we also start a timeout counter.
The remote module receive the message and call “println” in MyHostModule. This may be a plain module, but it can also be a C#, Python, Java, C/C++ function on the host computer.
I need to dig into the details later as I have a few loose ends here at present. How do we call a module on multiple devices etc – we need a broadcast and selection mechanism etc.
As the remote function finish it will return a Plain event. Our VM will receive this event and forward it to the calling module. But, it will also respond with a Timeout if we do not get a response within a given time frame.
Plain is designed to allow simple code – we can chose to code all this with a “don’t care” attitude, or we can add On statements to control the behaviour depending on the success of our call.
use MyHostModule
module MydeviceModule
MyHostModule.Println ("Hello World")
On Timeout(uint32 msTimeout)
// no responce, we might have
// lost communication
On Continue
// it's been printed
End
End
In this second example we catch the events as they return.
use MyHostModule
module MydeviceModule
spawn MyHostModule.Println ("Hello World")
End
This example add the keyword spawn rather than the default “call”. The difference is that Spawn makes the call, but will continue directly without waiting.
Many loose ends we need to discuss here…
to be continued in part 2…